Introdução
O modelo de dados dimensional (Star Schema) é o padrão mais adotado como estrutura de dados em data warehouses.
Este artigo questiona se este modelo de dados ainda é a melhor opção de modelagem à luz de novas tecnologias surgidas nos últimos anos e do advento da computação em nuvem
Para isso iremos comparar o modelo dimensional com um outro baseado em uma grande tabela única (OBT – One Big Table), defendido por Dave Fowler durante uma palestra em 2020.
Modelo Dimensional
Tradicionalmente o modelo de dados utilizado para bancos relacionais é o modelo 3NF. Sua principal característica é um alto grau de normalização proporcionando uma máxima economia de espaço através da menor duplicação de dados possível.
Esse modelo funciona bem para processamento transacional (OLTP) mas deixa muito a desejar para processamento analítico (OLAP). Isso se deve principalmente à sua complexidade de relacionamentos que gera não só uma dificuldade para os profissionais que vão gerar as análises, mas também uma lentidão para a execução de queries complexas.
É sempre importante lembrar que enquanto no OLTP lidamos com muitas transações pequenas, no OLAP predominam as operações de leitura de grandes quantidades de dados simultaneamente
A necessidade crescente de data analytics na década de 90 levou à introdução do modelo dimensional proposto por Ralph Kimball em 1996. O esquema mais utilizado para esse modelo é o star schema e neste artigo apenas iremos nos referir a ele quando tratamos do modelo dimensional.
O star schema,, de-normalizado em relação ao 3NF, possui a seguinte característica principal: possui uma fact table que referencia diversas dimension tables
A fact table contém as chaves de ligação com as dimension tables e métricas com a maior granularidade desejada possível.
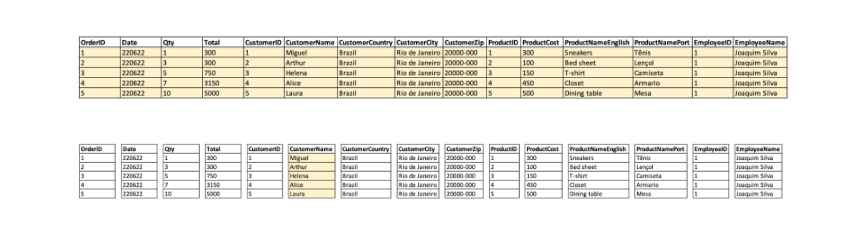
A comparação entre os dois modelos pode ser melhor entendida no exemplo simples abaixo:

OBT – One Big Table
A ideia de utilizar um modelo baseado em uma grande tabela parte do princípio de que as tabelas fact e dimension devam ser integradas em uma só grande tabela que possua em cada registro todas as informações desejadas de todas as tabelas. Conforme imagem abaixo:
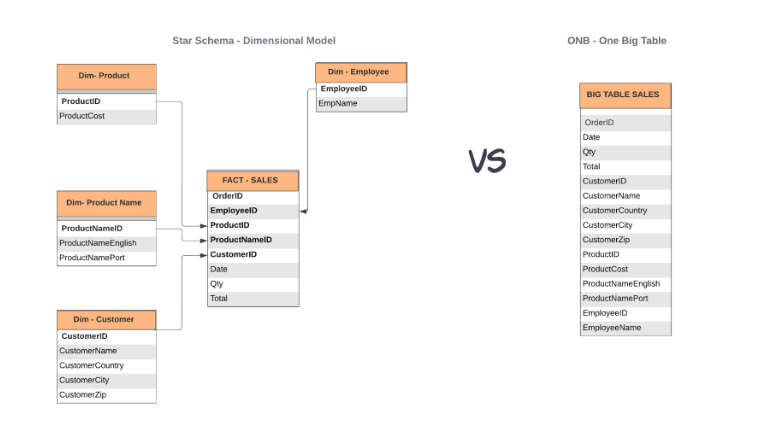
Este “tabelão” simplifica o entendimento e facilita bastante o trabalho dos analistas de BI que vão ter todos os dados em uma só tabela sem terem de se preocupar com JOINs e relações entre tabelas.
Entretanto, essa ideia pode parecer pouco eficiente em termos de custo e desempenho uma vez que seu grau de normalização é zero. Isso significa que a necessidade de storage é muito superior e que a quantidade de dados a serem lidos em uma consulta é também muito maior.
Basta imaginar, por exemplo, que um mesmo produto que apareça em diversas transações vai ser duplicado em cada um dos registros destas transações.
No entanto, essa equação pode não ser mais válida com as tecnologias disponíveis hoje em dia, principalmente através dos provedores de cloud computing, como veremos a seguir.
Star Schema vs OBT
Quando foi introduzido, o modelo dimensional trouxe três grandes vantagens para o OLAP: Custo, Desempenho e Simplicidade.
Antes de mais nada é importante ter em mente que o modelo dimensional foi introduzido há mais de 20 anos. Portanto antes de sequer existir hadoop, computação em nuvem e todo um ecossistema poderoso para lidar com big-data
Vamos analisar ambos os modelos à luz das tecnologias atuais.
Custo
Até o advento da computação em nuvem, o armazenamento era extremamente caro e qualquer esforço para otimizar o espaço necessário teria um impacto grande no custo.
Hoje em dia, os dados podem ser armazenados em serviços de computação em nuvem como por exemplo o S3 da AWS a um custo muito baixo.
Além disso, novos formatos de arquivos colunares como o Apache Parquet são extremamente eficientes tanto no que diz respeito à pesquisa como compressão de dados.
Da mesma forma, bancos de dados colunares permitem alta eficiência de escaneamento de dados. Usando nossas tabelas como exemplo, ao fazer uma query filtrando pela coluna CustomerName, apenas esta coluna é varrida, reduzindo o tempo e volume de dados varrido a uma fração do total.
 Levando-se em conta a economia em termos de mão de obra altamente especializada obtida com simplicidade de ter uma só tabela, podemos concluir que uma eventual diferença de custo em termos de armazenamento seria amplamente compensada pela redução dos custos de pessoal.
Levando-se em conta a economia em termos de mão de obra altamente especializada obtida com simplicidade de ter uma só tabela, podemos concluir que uma eventual diferença de custo em termos de armazenamento seria amplamente compensada pela redução dos custos de pessoal.
Desempenho
A utilização de formatos de banco colunar associado à uma plataforma de big data do ecossistema hadoop torna também o desempenho de uma grande tabela extremamente rápido. De certa forma podemos dizer que o uso do Presto com o formato Parquet seria equivalente ao indexamento automático de todos os campos de um banco tradicional. Dá para imaginar a facilidade e flexibilidade que essa combinação nos traz. A Amazon AWS inclusive possui o Athena que é o Presto serverless e sob-demanda.
Um estudo realizado pela Fivetran concluiu que o desempenho com produtos de cloud data warehouse como por exemplo o Amazon Redshift é 25-50% mais rápido do que o modelo tradicional.
Simplicidade/Usabilidade
Ainda que este seja um conceito subjetivo que provavelmente irá gerar controvérsias, acredito que o modelo OBT seja mais simples e intuitivo, especialmente para analistas de negócio que não costumam ser técnicos. Este tipo de usuário está acostumado ao conceito de uma grande tabela como planilhas e não necessariamente saberiam construir queries com JOINS necessárias no Star Schema
As figuras 4 e 5 abaixo representam um exemplo de análise com o QuickSight, ferramenta de Analytics da AWS utilizada para criação de dashboards. Enquanto que na primeira figura é necessário configurar as relações para a obtenção dos campos de cada tabela, a outra figura mostra como seria a configuração no caso de uma tabela única.
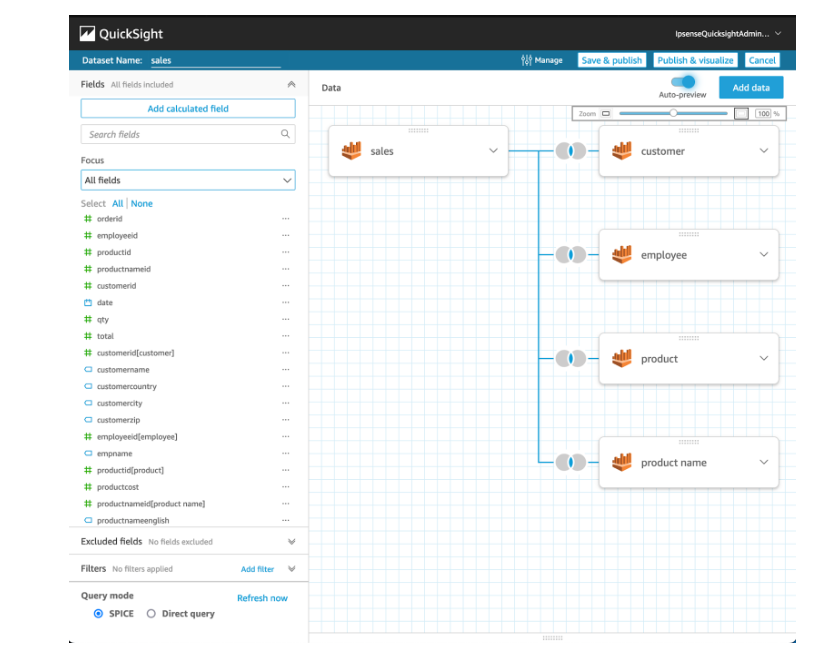 Figura 4
Figura 4
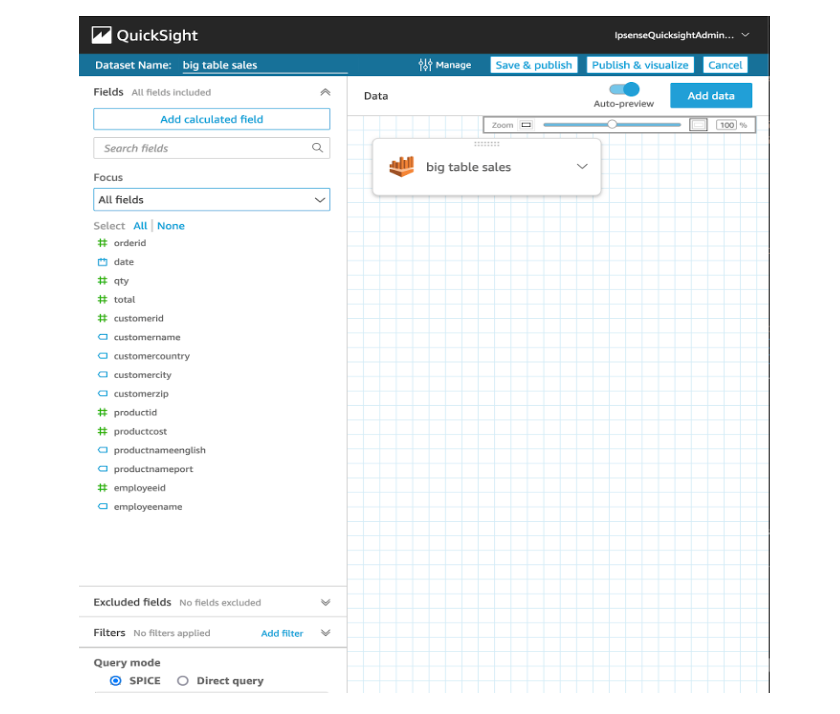 Figura 5
Figura 5
Da mesma forma demonstramos abaixo a diferença de análise através de SQL. Como podemos notar, não há preocupação com JOINs ao usar uma tabela única. Fig 6 e 7.
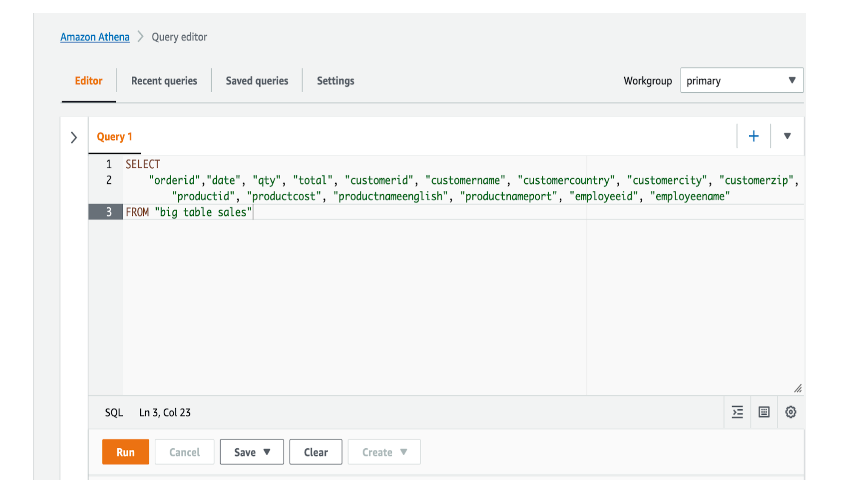
Figura 6
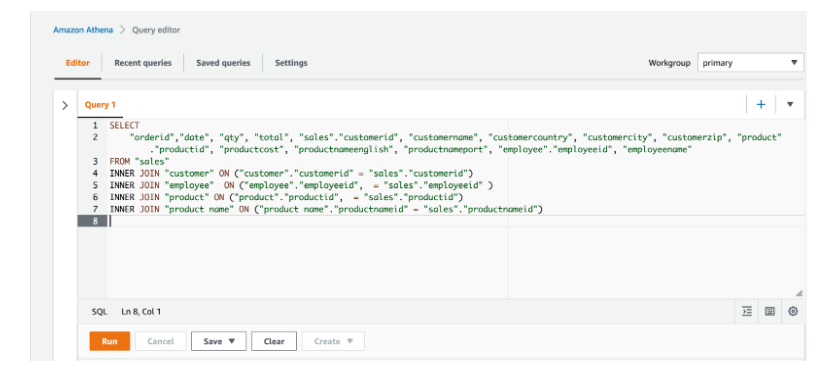
Figura 7
No passado, a introdução do modelo dimensional trouxe enormes benefícios de custo, desempenho e simplicidade ao mundo de BI.
Agora podemos contar com novas tecnologias que foram construídas para resolver a necessidade de lidar com grande volumes de dados, como: Hadoop, Presto, Cloud Data Warehouse, formatos colunares e tabelas em formato aberto mantendo os mesmos benefícios já conquistados.
A IPsense é uma empresa 100% focada em fornecer soluções de Cloud Computing para o mercado. Além disso, é um parceiro avançado da AWS com especialização em Data Analytics e tem realizado a implantação de diversos data lakes e data warehouses na AWS utilizando esses conceitos e tecnologias. Entre em contato com nossa equipe.


